
3 min read
Honchō Scoops Up Two UK Search Awards!
It’s official, we've added not one, but two shiny trophies to our awards cabinet! We’re over the moon to share that we’ve triumphed at the UK Search...
2 min read
PRAW stands for “Python Reddit API Wrapper” and is an easy and fun module to start collecting data from Reddit. The official documentation can be found here: https://praw.readthedocs.io/en/latest/index.html.
Assuming you have a Reddit account already
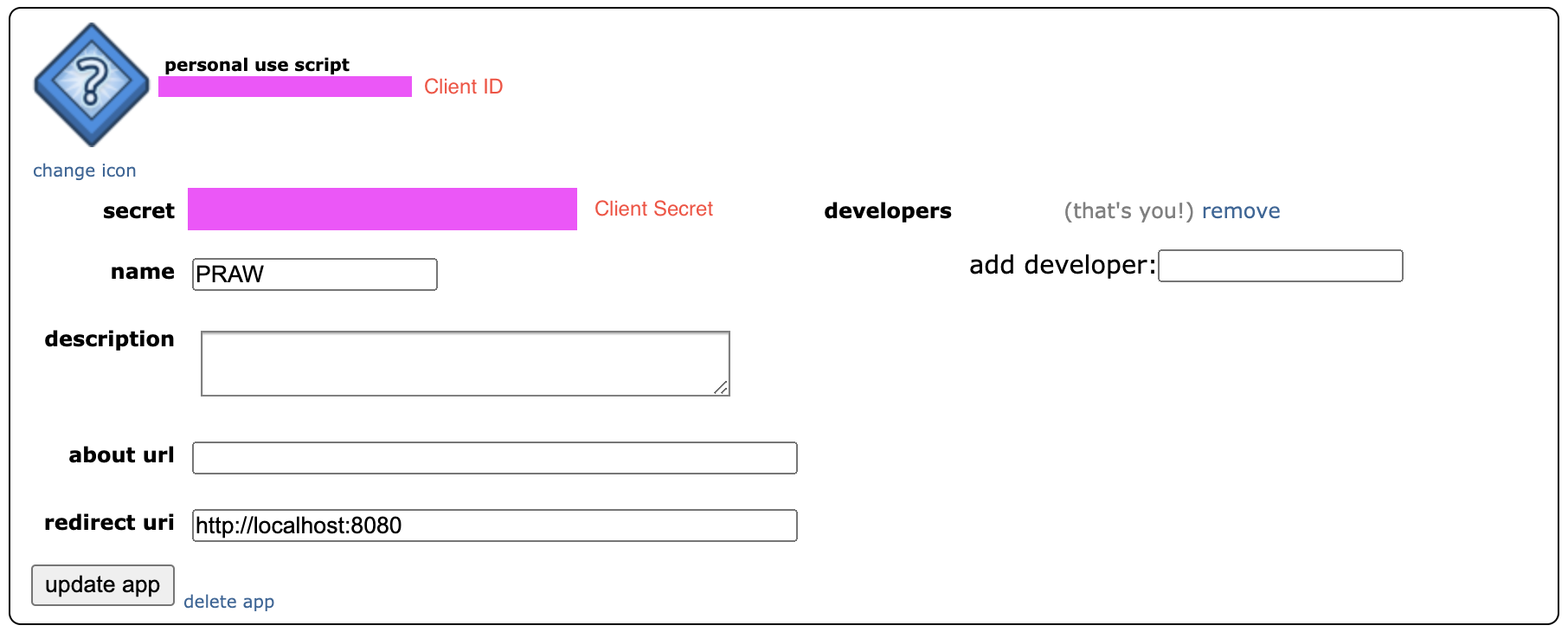
Visit: https://www.reddit.com/prefs/apps
At the bottom, you will see “Create App” or similar depending on whether you have existing applications in your account.

Note down your Client ID & Client Secret (image below where to find them).
Install PRAW in Python. PRAW supports Python 3.6+. The recommended way to install PRAW is via pip
pip install praw
You need an instance of the Reddit class to do anything with PRAW. The following will be looking at a “read only” submission instance. In basic terms allowing us to look at submissions in a subreddit as if you were browsing.
Create a new python file and, using the Client ID and Client Secret, enter your information. The user agent can be left as it is.
import praw
reddit = praw.Reddit(
client_id=”my client id”,
client_secret=”my client secret”,
user_agent=”my user agent” )
To test if your instance is working use:
print(reddit.read_only) # Output: True
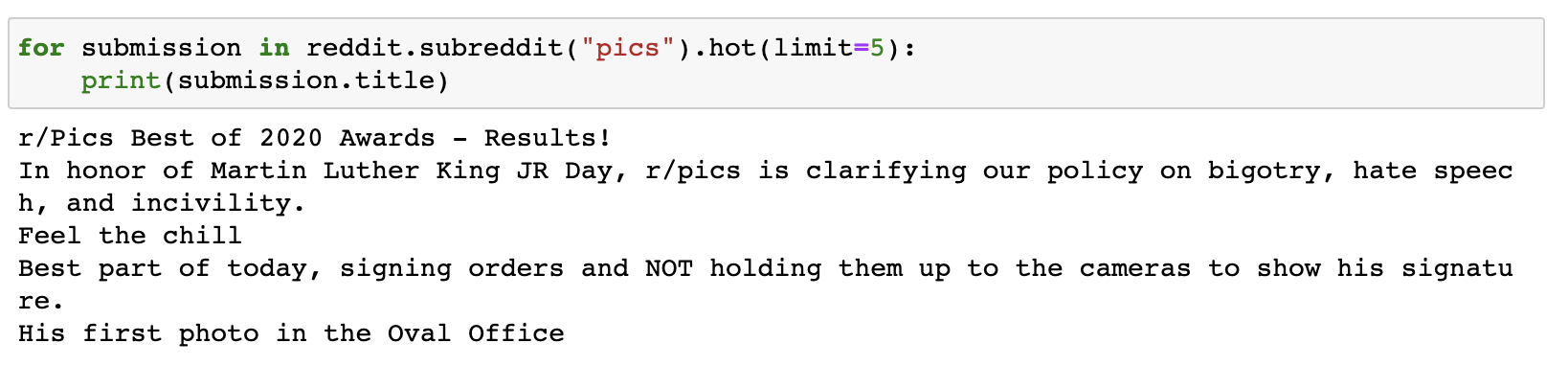
Choose a subreddit that you want to get submission data for. For my example I’ll use r/pics – where everyone on LinkedIn and Twitter finds their “original” content.
A quick, simple operation – print the submission titles for the top 10 hottest posts right now. In the same python file from above add:
for submission in reddit.subreddit(“learnpython”).hot(limit=10):
print(submission.title)
You should have the top 10 post tiles printed. As seen below:
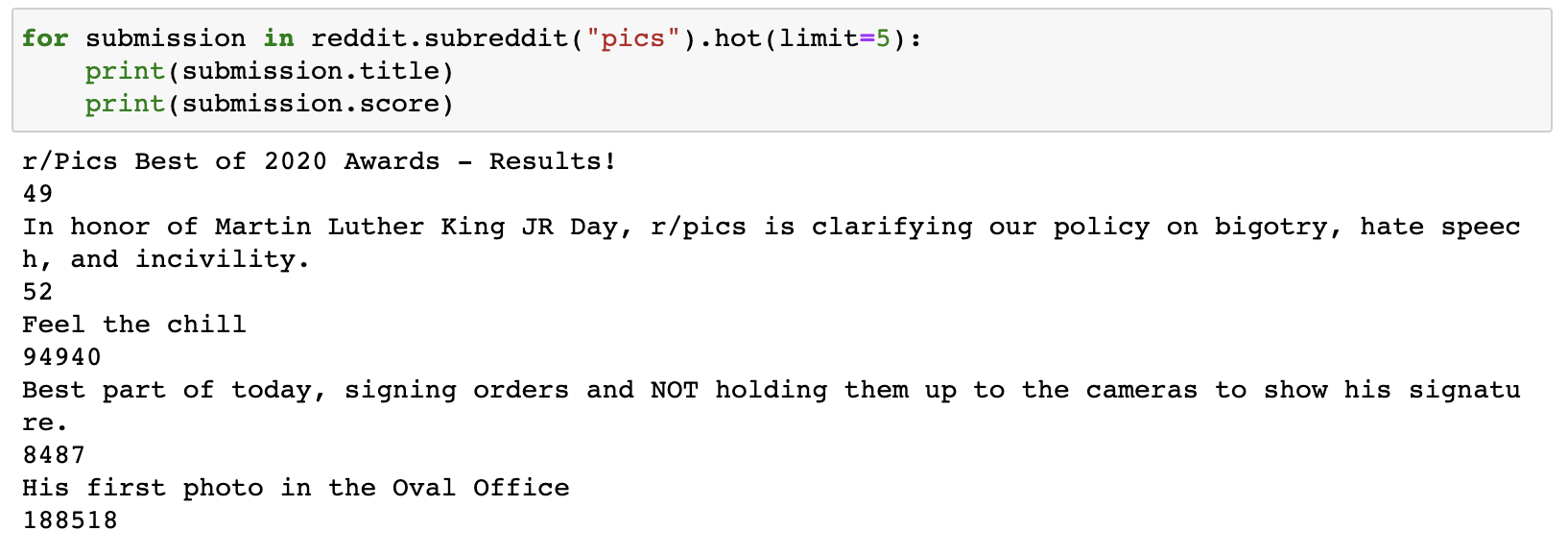
With PRAW we’re able to extract a lot more than just the title posts. Below is my table, I have included others which I typically use.
|
Attribute |
Description |
|
author |
Provides an instance of Redditor. |
|
num_comments |
The number of comments on the submission. |
|
score |
The number of upvotes for the submission. |
|
title |
The title of the submission. |
|
url |
The URL the submission links to, or the permalink if a self-post. |
Since attributes are dynamic , there is no a guarantee that attributes seen in my example or other examples will always be present, nor will any list ever really be 100% accurate. The best way to see all available attributes at any given time is to use the following:
import print
# assume you have a Reddit instance bound to variable `reddit`
submission = reddit.submission(id=”39zje0″)
print(submission.title) # to make it non-lazy
pprint.pprint(vars(submission))
Hopefully this has been an easy introduction to PRAW and using the Submission instance. While there is plenty more you can do from here, such as adding this all into a dataframe and using NLP to uncover sentiment and trends, we’ll leave that for another post.
If have any questions contact us at hello@honchosearch.com or find us on Linkedin.
Subscribe to our email list to receive blog updates and other Python How-Tos directly to your inbox.





3 min read
It’s official, we've added not one, but two shiny trophies to our awards cabinet! We’re over the moon to share that we’ve triumphed at the UK Search...

5 min read
Understand ecommerce attribution models which attribution models can maximise your marketing efforts and ROI.

3 min read
Explore how social commerce is changing the way we shop online, blending social interactions with digital commerce for a seamless buying experience.